

El pasado 8 de noviembre se celebró en la sede de Caixa Forum en Madrid, el II encuentro Agridata Summit, dedicado a la transformación digital y el big data en el sector agrario y alimentario.
Un foro que ha conseguido mantener el interés despertado y la calidad de las contribuciones de la primera edición, siendo a la vez capaz de duplicar el número de asistentes. Sin duda el evento se consolida, con buenas perspectivas para futuras ediciones.
Desde la inauguración por la ministra García Tejerina quedó clara la relevancia que la I+D va a tener en esta transformación digital en los próximos años. Y este margen de mejora que va a proporcionar al sector agrario y alimentario, será liderado por la explotación de datos, junto a la automatización. Dentro de este preámbulo se anunció la creación del Grupo Focal de digitalización y Big Data en el sector agroalimentario y forestal en el medio rural, una iniciativa de la que ya se empezaba a hablar en el I Agridata Summit hace ya un año.
La agricultura de precisión fue una de las estrellas del encuentro, tanto en su faceta de recopilación de datos vía sensores presenciales o remotos, como en la faceta de actuaciones de precisión (regadío, etc.) y de sistemas automáticos de decisión.
El desarrollo de ecosistemas de datos van a suponer el tercer pilar, junto al impulso a la conectividad y el apoyo a la transformación digital, del programa de transformación digital que impulsa Red.es. El laboratorio de innovación BNElab, que recientemente ha lanzado la Bibilioteca Nacional de España fue puesto como referente de las futuras acciones de desarrollo de estos ecosistemas. ¿No podríamos tener un Agrolab de este tipo en el futuro en un organismo como el INIA? ¿Por qué no? Como vimos a continuación se trata de una idea que está cogiendo fuerza en el sector.

¿Cómo? Porque hasta tres intervenciones dedicaron su tiempo a presentar iniciativas de Digital Innovation Hubs. En primer lugar Ricardo Gómez de la Junta de Andalucía y, a continuación, Joan Bonany del IRTA, presentaron las repectivas iniciativas de sus gobiernos autonómicos. Pero fue Marta Conde de CDTI quien desarrolló los detalles de estas iniciativas, que pretenden potenciar el desarrollo del tejido industrial y económico desde el conocimiento generado en los centros de I+D. Para mí, probablemente uno de los temas más importantes que se trataron en el este Agridata Summit, claro, desde el punto de vista de un instituto de investigación y tecnología.
Otra iniciativa interesante, a mi juicio fue Agrirouter que pretende proporcionar interopeabilidad a los datos generados por la maquinaria agrícola superando las diferencias de los distintos fabricantes. Dicha iniciativa fue presentada tanto por Fendt, como por CEMA, la Asociación Europea de Maquinaria Agrícola. A mí me dejó un poco frío que se tratara de una plataforma en lugar de un protocolo, ya que dificulta a mi juicio la participación de nuevos sistemas y por tanto la estandarización. Pero es un paso adelante.
Otra iniciatica interesante, también presentada por Ulrich Adam, secretario general de CEMA, fue un futuro Código de Buenas Prácticas con los Datos Agrícolas, que ayudará a resolver cuestiones como la propiedad de los datos generados en las explotaciones. Una iniciativa muy interesante.
¿Qué más? Mucho. Lo mejor del encuentro las palabras de Félix Roncero que nos puso los pies en la tierra, y nos presentó sus más de 30 años de experiencia con la tecnología digital aplicada a la producción de leche de vaca.
Hubo muchos más contenidos, pero no es mi objetivo realizar un reporte completo, si no compartir mis notas personales. Mi recomendación es que cualquier interesado esté alerta para no perderse el III Agridata Summit, que sin duda va a ser un éxito.
Desde aquí quiero felicitar a todos los organizadores del encuentro porque fue satisfactorio en todos los sentidos, y a los patrocinadores por apostar tanto por el sector como por esta conferencia en particular, que estoy seguro va a aportar mucho a la comunidad y va a ser el germen de muchas iniciativas para la mejora del sector a través de la digitalización.


Hoy arrancamos una nueva iniciativa en Agrobits. Una sección de entrevistas para ilustrar la relevancia de los sistemas de información y el desarrollo de software en la investigación agraria y alimentaria. Para esta primera edición, y aprovechando que estamos a punto de celebrar por segunda vez el Global Sprint de Mozilla Science Lab, hemos invitado a nuestro compañero, y sin embargo amigo, Eduardo López Senespleda a que nos cuente su experiencia.
Agrobits - Buenos días Eduardo, bienvenido a Agrobits. ¿Podrías contarle a nuestros lectores quien eres y a qué te dedicas?
Eduardo - Hola, buenos días Antonio. Pues soy un ingeniero de montes, doctor, pero ante todo una persona muy familiar (y padre orgulloso) además de friki. Trabajo en el CIFOR, como tecnólogo, principalmente en labores de apoyo a la investigación. Estoy especializado en ecología y suelos forestales. Y entre otras cosas, también trato de dar rienda suelta a mi afición por la tecnología aplicándolo, siempre que me resulta posible, a mi trabajo. Por ejemplo, con el desarrollo de “artilugios” usando software y hardware libre (concretamente Arduino). Últimamente estaba tratando de elaborar y calibrar unas sondas de humedad edáfica, entre otras cosas que tengo en mente.
A - ¿Cuánto tiempo llevas trabajando en el INIA?
E - Entré en esta casa allá por el año 2003, de la mano de mi mentor, recientemente jubilado, Gregorio Montero. Gracias a él conocí esta profesión antes de iniciar mis estudios universitarios, profesión que me enamoró y que, todavía a día de hoy, me fascina. Luego tuve la inmensa suerte de conocer y trabajar con Otilio Sánchez Palomares, también ya jubilado hace tiempo. Él me encaminó hacia la ecología forestal y los suelos forestales. Aunque fue profesor mío en la carrera, no fue hasta llegar aquí que descubrí la enorme faceta personal y profesional que escondía, siendo posteriormente uno de mis directores de tesis. He de decir, que me considero tutelado en mi camino por el INIA por dos de los mayores profesionales, cada uno en su campo, que creo que ha habido. Dos de los “grandes” forestales.
A - ¿Cómo describirías tu relación profesional con los sistemas de información y/o con el desarrollo de software?
E - Mis padres tuvieron el acierto de hacer el esfuerzo y comprar un ordenador cuando yo era pequeño, uno de los primeros Amstrad CPC 464, donde hacía mis pinitos en BASIC. Posteriormente me regalaron un PC de la casa Bull, con procesador 8086 y doble disquetera de 5 ¼ y sin disco duro, en el que había que cargar el MSDos en memoria al arrancar. También eché horas delante de este aparato. Mi padre, radioaficionado e ingeniero frustrado pero con una enorme afición por la electrónica, decidió montar una vez un PC que fuimos comprando por componentes, comprados mes a mes. Así tuvimos nuestro primer PC con procesador Intel 486 … a partir de ahí, siempre me han acompañado los ordenadores… Profesionalmente, casi toda mi actividad está ligada a los datos y el software para procesarlos y exprimirlos. Considero que tengo facilidad para aprender y utilizar lenguajes de programación, pero la mayor parte de las ocasiones son para usos muy puntuales.
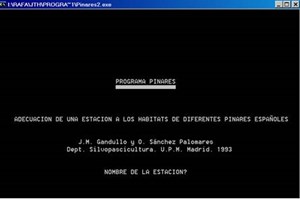 Pantalla de presentación del programa PINARES original
Pantalla de presentación del programa PINARES original
Hace ya casi diez años que mi amigo Rafael Alonso y yo hablábamos en nuestras tertulias compartiendo ubicación en “la cueva”, aquí en el INIA, sobre el desarrollo de un programa que nos facilitara todos los cálculos que hacíamos con frecuencia. Una especie de programa “Pinares” como el antiguo desarrollado por Gandullo y Sánchez Palomares, para asistir a los gestores forestales en la toma de decisiones. Y en nuestros delirios imaginábamos cada vez más funcionalidades a dicho programa…. Hasta ahora. El equipo de personas que participaron y participan en su desarrollo está formado por ingenieros de montes e informáticos. Los primeros (Rafael Alonso, Gregorio Montero y yo mismo) damos las pautas, explicamos los algoritmos, traducimos “nuestro” lenguaje. Los segundos, Álvaro Calleja en una fase inicial, pero sobre todo Fernando Cavero son los encargados de darle forma.
 Pantalla de presentación del actual ModERFoRest
Pantalla de presentación del actual ModERFoRest
Ahora mismo estamos envueltos en la ardua tarea de terminar tal programa: ModERFoRest (Modeling Environmental Requirements for Forest Restoration). A ver, yo no soy programador, pero puedo comunicarme y entenderme con Fernando, y así vamos tratando de resolver, en conjunto, las vicisitudes por las que va pasando ModERFoRest.
 La ortografía de ModERFoRest se ganó este meme durante las jornadas
La ortografía de ModERFoRest se ganó este meme durante las jornadas
A - El año pasado, participaste en la edición madrileña del Global Sprint de Mozilla Science Lab con este proyecto. Cuéntanos en qué consiste, y qué te llevo a participar.
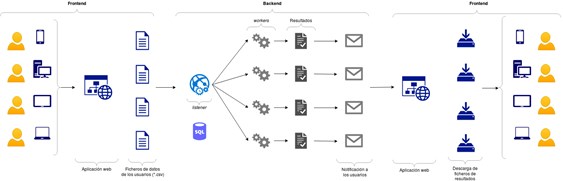
E- ModERFoRest es un programa que inicialmente está pensado para asistir a los gestores forestales en la toma de decisiones sobre la consideración de especies forestales en planes de repoblación, de restauración, de gestión adaptativa, etc. El software implementa dos algoritmos, con propiedades distintas, para la estimación del nicho y de las correspondientes áreas potenciales de expansión, en función de las condiciones climáticas y edáficas. Incluye las principales variables predictoras para 18 especies forestales arbóreas, frondosas y coníferas. El lenguaje de programación es C++, y el entorno de desarrollo es Qt. ModERFoRest incluye librerías de código abierto como Armadillo para el cálculo de álgebra matricial, y posee licencia GPL3.
ModERFoRest estaba inicialmente pensado para ser descargado e instalado en el ordenador del usuario, aprovechando la capacidad de cálculo que tuviera su ordenador. Pero las dificultades que aparecían una y otra vez en la compilación para su uso en plataformas Windows hizo que Fernando y yo acudiéramos al Global Sprint del año pasado, a la edición de Madrid que organizaste. Íbamos, sobre todo, con la intención de darlo a conocer y tratar de “enganchar” a alguien en el proyecto, alguien que pudiera darnos una pista o echar una mano con dicho problema.
A - ¿Y consideras que se cumplió ese objetivo?
Sí, en gran medida. Por desgracia llegamos tarde a la presentación por video conferencia, y no pudimos darle la difusión global deseada. Pero sin duda fue satisfactorio, dando un nuevo soplo al proyecto.
A - Y tanto un nuevo soplo. Un nuevo soploEl impacto de esa jornada va a afectar incluso a la arquitectura y modo de distribución de la aplicación, ¿no es cierto?
E - Efectivamente, de la interacción con los asistentes surgieron ideas que fraguaron en la cabeza de Fernando y han transformado el concepto del programa. En su concepción inicial tenía una arquitectura en la que era un archivo descargable y que debía instalarse en el ordenador. Actualmente se ha derivado hacia el concepto de servicio web. En este caso, el usuario, una vez registrado (de forma gratuita), puede cargar sus datos y definir las opciones de cálculo y las salidas que desea. El servicio es diferido, es decir, no tiene que permanecer conectado hasta que obtenga los resultados. Cuando todo esté preparado, recibirá un correo electrónico en el que se le avisa de que ya están disponibles los resultados para su descarga y análisis. Creo que eso, unido a otras cuestiones va a dotar de una gran flexibilidad al proyecto.
A - ¿Volveríais a participar?
E - Sí, sin duda. Por mi parte no veo inconveniente alguno. Y seguro que Fernando comparte mi opinión.
A - Pues falta muy poco para activar la nueva convocatoria, ¡reservad el 1 y el 2 de junio!. ¿Quieres añadir algo? ¿Qué te deberíamos haber preguntado?
E - Poco más, sólo añadir un último comentario sobre el desarrollo de soluciones en investigación con Arduino. Creo que este tipo de plataformas pueden ser de gran utilidad en organismos como éste. Es más, creo en la necesidad de tener un laboratorio “tecnológico” en el CIFOR, del tipo que alguna vez me ha comentado Jorge García, compañero nuestro y sobre todo tuyo, que dirigía en el Instituto Carlos III. Un laboratorio que permita obtener soluciones a problemas concretos de la investigación en campo que desarrollamos. Creo que tenemos gente motivada y cualificada para ese desempeño, sólo hay que darles la oportunidad de ponerlo en práctica.
 ¿CIFORlab?, ¿INIAlab?, ... eso se merece otro meme
¿CIFORlab?, ¿INIAlab?, ... eso se merece otro meme
A - Y por último, no lo haremos público para no poner a nadie en un compromiso pero, ¿a quién deberíamos entrevistar en la próxima entrega?
E - ...
A - Tendréis que esperar a nuevas edidciones de estas entrevistas para conocer su interesante respuesta 2x1. Muchas gracias Eduardo, hasta la próxima.
E - Muchas gracias a ti por la oportunidad. Seguimos en contacto para ir a la nueva edición de este año del Mozilla Science Lab.
Agrobits - Y eso ha sido todo por esta edición, espero que os haya resultado interesante. Y por supuesto si queréis participar con vuestros proyectos software, o queréis recomendarnos a alguien para entrevistarlo, ¡no dejéis de poneros en contacto! Hasta el próximo agrobits.

El pasado día 8 de febrero tuvo lugar en el aula de informática del INIA un taller de introducción para los usuarios del INIA que comenzarán a utilizar el supercomputador Finis Terrae II del Centro de Supercomputación de Galicia (CESGA), en base al acuerdo/contrato entre nuestras organizaciones.
Pablo Rey y Aurelio Rodríguez del CESGA viajaron desde Santiago de Compostela, y en un programa apretadísimo nos explicaron la arquitectura del supercomputador, los modos en que pueden acceder los usuarios, el funcionamiento del sistema de colas para los trabajos de cálculo y algunos conceptos de computación paralela para el uso de las aplicaciones en sistemas con múltiples núcleos (cores).
La recepción fue muy buena por parte de los investigadores y técnicos del INIA. Tuvimos un lleno completo de la sala de informática, incluso algunas personas se quedaron sin poder asistir. Los participantes vinieron del Departamento de Mejora Genética Animal y del CIFOR, en su mayor parte, y también del Departamento de Biotecnología.
Se resolvieron dudas generales, estrategias para la optimización de las tareas lanzadas y también dudas particulares para la instalación de aplicaciones específicas en el sistema.
Lamentablemente, olvidamos tomar una foto de los asistentes para ilustrar esta entrada.
Nota: los interesados en el curso pueden encontrar información sobre una versión semejante en la web del CESGA (https://www.cesga.es/es/actuais/ver_curso/id_curso/2311), y grabaciones en Youtube de un curso semejante al impartido en el INIA.
Primera parte:

Segunda parte:



Hoy 10 de noviembre de 2016, hemos realizado un mini taller de desarrollo con Javascript para crear sitios de divulgación científica, tomando como base un ejemplo de nuestro compañero @jmadrigalolmo.
Este tutorial fue publicado originalmente en:
https://github.com/inia-es/semanaCiencia16_iiff
Un ejemplo de la herramienta final se encuentra en:
https://github.com/inia-es/semanaCiencia16_iiff_src
Explicaciones explorables
Explicaciones explorables es un término acuñado por el ingeniero y diseñador Bret Victor para referirse a un documento interactivo, de carácter científico-técnico, que explica determinado concepto dando la oportunidad al lector de explorar los cambios que ocurren en el sistema o proceso cuando se modifican algunas de las variables que lo controlan.
Las páginas web y las aplicaciones para móvil o para tablet son el lugar ideal para estas Explicaciones Explorables, pero no significa que sea el único medio en el que se pueden construir. Una alternativa podrían ser los libros interactivos, con mecanismos simples de papel.
En este taller vamos a ver como podemos construir una sencilla web que nos ayude a explicar la relación que hay en un incendio forestal entre el material inflamado, la velocidad de propagación del fuego, el tamaño de la llama, y los medios de extinción más adecuados en cada caso.
Para ello construiremos progresivamente una página web interactiva con Javascript.
Estructura básica de una página web
Como algunos sabréis las páginas web están escritas en lenguaje HTML. La estructura más básica que podemos construir es:
Antes de seguir creemos un fichero llamado en una carpeta adecuada de nuestro ordenador, y copiemos o mejor, escribamos en él, el código de ejemplo. Después podemos abrir dicho fichero con nuestro navegador, y podremos ver el resultado de la página web.

HTML es un lenguaje de etiquetas. Cada sección del documento está comprendida entre una etiqueta de apertura y su correspondiente etiqueta de cierre .
Las etiquetas y limitan el princpio y el final del documento. También podemos ver que el documento se divide en dos secciones principales, una limitada por la etiqueta donde se indican aspectos de configuración de la página web; y otra limitada por la etiqueta donde está el contenido de la página propiamente dicho.
En este taller pasaremos de puntillas sobre muchos aspectos de HTML. Los interesados en profundizar en esta materia pueden seguir la documentación de MDN (Mozilla Developer Network): https://developer.mozilla.org/es/docs/Learn/HTML
Introducción a Javascript
Desde que el navegador Netscape incluyera por primera vez la posibilidad de ejecutar código Javascript en 1995, este lenguaje se han convertido en el estándar para desarrollo en el lado del cliente de la web.
Javascript tiene una sintáxis de la familia de C, similar a la de muchos lenguajes populares como C, C++, Java o PHP. Para incluir código Javascript en nuestra página web hacemos uso de la etiqueta .
La etiqueta puede ser incluida tanto en la sección como en la sección . Puesto que los ficheros HTML se ejecutan conforme son leídos, colocar el bloque al final de la sección , da ciertas garantías que el contenido completo de la página web ha sido cargado antes de ejecutar el código.
Este ejemplo ejecuta la función que indica al navegador que queremos mostrar un aviso, que requiere la aprobación ('Aceptar') del usuario antes de continuar.

Busquemos un aliado: Firebug
Firebug es un plugin de Firefox que facilita el desarrollo de páginas web y aplicaciones. Se instala fácilmente desde el gestor de complementos de Firefox. Una vez instalado, Firebug aparece con el icono de un pequeño insecto en la barra de herramientas del navegador.

La suite de Firebug tiene distintas herramientas que nos facilitan el trabajo de desarrollo: Consola, HTML, CSS, Script, DOM, Red y Cookies.

La herramienta Console nos mostrará los mensajes de error que genere nuestro código Javascript, pero también podemos acceder a ella haciendo uso del comando .

También es posible escribir código Javascript directamente en la consola, lo que la hace una manera ideal de realizar pruebas y aprender interactivamente.

Un viaje rápido por Javascript
Este taller, por su brevedad, solo pretende mostrar algunas características generales de Javascript, y unos pocos de los detalles que lo diferencian de otros lenguajes de programación.
Podemos hacer el siguiente recorrido directamente en la consola que abrimos en la sección anterior:
Javascript tiene detalles bastante avanzados. Si os habéis fijado, las funciones son objetos que tienen algunas funciones incluídas por defecto, como . Por ejemplo, podéis hacer también . Estas características hacen que sea un lenguaje realmente muy flexible.
Una Explicación Explorable
Vamos a crear una sencilla página web, que muestre la fórmula de Byram y permita explorar su evolución con algunos valores para la velocidad de propagación y los materiales del incendio.
En primer lugar creamos una sencilla web con las fórmulas, los datos y un ejemplo de la parte explorable.
Hemos introducido un par de etiquetas nuevas, como
para construir la tabla de datos, o para dar enfásis. Además hemos creado añadido las ecuaciones en forma de gráficos GIF (usando la herramienta online https://www.codecogs.com/latex/eqneditor.php).
Para añadir las imágenes podéis descargarlas del sitio web (https://github.com/inia-es/semanaCiencia16_iiff_src/tree/gh-pages/img). Este sitio web tiene todo el código de este ejemplo, pero si lo descargáis ahora arruinareis parte de la diversión.
Haciendo un sitio interactivo
Para esta parte del tutorial vamos a hacer uso de la librería Tangle. Podemos descargar los ficheros en http://worrydream.com/Tangle/download.html, y ponerlo en una carpeta de nuestro proyecto.
Ahora lo añadimos a nuestra web añadiendo:
a la sección de nuestra página web.
Ahora vamos a identificar la velocidad de propagación como un parámetro de entrada. Para ello vamos a modificar el texto por el siguiente código.
Y en la sección incializamos dicha variable:
# Generando valores de salida
Ahora vamos a hacer que el valor de longitud de la llama varie con la velocidad. Primero, identificamos la longitud de la llama como una variable del modelo, sustituimos por algo como:
Añadimos una función que calcule el valor de la llama. Vamos a usar una función de prueba, que nos permite probar el sistema interactivo. En el siguiente bloque usaremos la fórmula de Byram correctamente.
Y usamos esa función para actualizar el valor de en el modelo de Tangle:
Matemáticas en Javascript
Vamos a crear una función en Javascript para la fórmula de Byram. Es más fácil de lo que parece:
Ahora usaremos esta fórmula en nuestra función
Mejora estética
Vamos a mejorar un poco el aspecto de nuestro proyecto. En primer vamos a mejorar el aspecto de nuestra interfaz. Añadiremos parámetros a nuestro modelo para que admita decimales en la entrada y podamos darle un rango mínimo y máximo de valores, lo haremos con las etiquetas , y :
En segundo lugar vamos a dar formato a la salida, para poder ignorar los decimales que no necesitemos. Lo haremos con la etiqueta . Esta etiqueta formatea la salida haciendo uso de la descripción de formatos de la librería estándar de C (, , ...). Ver http://www.manpages.info/linux/sprintf.3.html
También vamos a mejorar el aspecto del sitio con Bootsrap (getbootstrap.com). Bootstrap es un framework CSS muy sencillo de utilizar para aquellos que no sabemos mucho de CSS, o no tenemos buena coordinación estética.
Guardamos los ficheros en la carpeta y luego los añadimos a la sección de nuestro HTML:
Para que Bootstrap dé una mejor estructura a nuestro contenido debemos poner todo el contenido entre las etiquetas:
Algunas etiquetas para mejorar el aspecto de nuestra tabla de datos:
Y un retoque (, , ) para mejorar el aspecto de nuestros resultados:
Para terminar la mejora añadimos la clase a las imágenes con las fórmulas:
Pocos dan tanto con tan poco esfuero.
Sofisticando el modelo
Hasta ahora hemos trabajado siempre con el mismo tipo de incendio, uno de pasto. Vamos a introducir ahora los otros tipos de incencios: matorral bajo y matorral alto.
Modificaremos para que sea una variable de entrada:
funciona como un selector horizontal como el que usamos para la velocidad. muestra solo uno de los valores contenidos según el valor que adopte la variable .
Ahora añadiremos la información de biomasa a Javascript, para poder usarla en la fórmula. Para ello usaremos un array:
Ahora solo nos queda introducirlo en la fórmula de Byram:
¡¡Enhorabuena!!, habéis construido vuestra primera Explicación Explorable.
Explicaciones visuales
Ahora vamos a añadir un elemento visual para mejorar la explicación.
Creamos una estructura haciendo uso de la capacidad de Bootstrap, para crear columnas. En cada uno vamos a insertar una imagen que explique el tamaño del incendio:

Cambiaremos el tamaño del incendio en función de la longitud calculada de la llama.
Vamos a añadir un identificador a la imagen que queremos modificar:
Para poder modificar su tamaño, creamos una referencia a este elemento en el código Javascript.
Calcularemos el tamaño del gráfico de la llama de manera proporcional al valor de longitud de la llama.
La longitud máxima de la llama en nuestro ejemplo es 24.07m. Como en cada navegador el tamaño del gráfico va a ser distinto, necesitamos averiguarlo en el código.
Ahora solo nos queda modificar la altura del fuego en la función update:
Hemos conseguido un tamaño de la llama interactivo, pero no es muy satisfactorio. Para hacer que las llamas crezcan hacia arriba, vamos a introducir un margen variable:
Para modificar la imagen de la recomendación, usaremos una estrategia parecida a la que hemos usado para modificar la llama, pero en lugar de modificar la propiedad mdificaremos la propiedad :
Y en Javascript creamos una función que seleccione la imagen para los distintos valores de longitud de la llama, y la aplicamos en nuestro update:
Buenas prácticas
Una vez que hemos llegado hasta aquí tenemos una aplicación interactiva que hemos intentado hacer atractiva para el público en general. Terminamos el tutorial con una pequeña mejora que no tiene repercusión funcional ni estética, pero mejora el diseño de la aplicación.
Vamos a evitar replicar los valores de biomasa en el código y en el HTML. Para ello tomaremos los valores de la tabla como origen de datos, y los utilizaremos en Javascript.
En primer lugar anotaremos los valores de la tabla con microdatos. Los microdatos describen más precisamente la información de una web, y permiten que sea explorada por buscadores con más información o utilizada por aplicaciones de terceros.
Usar microdatos es muy sencillo:
Para acceder a los valores usaremos la función que nos devuelve un elemento HTML. Para acceder a su contenido usamos su propiedad . Por último creamos una función que elimina la unidad de kg y nos devuelve un valor numérico.



El Global Sprint de Mozilla Science Lab es un evento a nivel mundial que se celebra anualmente. En él, investigadores, programadores, bibliotecarios y el público en general se reunen para hackear (en el buen sentido del término) participando en el desarrollo de proyectos de ciencia abierta y datos abiertos.
El año pasado participé a título personal colaborando con algunos de los proyectos, cualquier apoyo supone un paso adelante para los mismos. Este año, gracias a nuestros amigos de Medialab Prado, contaremos con un espacio en Madrid donde reunirnos y poder compartir impresiones y apoyarnos mutuamente en nuestros proyectos.
¿Qué se hará?
El programa oficial del evento es sencillo. Basta registrarse en la página web, y puedes echar un vistazo a los proyectos que han solicitado participar en el evento. Puedes apuntarte para colaborar en cualquiera, pero también puedes traer tu propio proyecto; trabajar en su mejora y/o divulgación, buscar colaboradores y mejorar su publicación como software libre, datos abiertos, etc.
Este año hay cuatro ramas de proyectos: herramientas, ciencia ciudadana, formación y datos abiertos. Hay algunos muy interesantes: Ecodata Retriever o Content Mine , pero yo estoy deseando ver los vuestros.
Después nos reuniremos en Medialab Prado, no olvides traer tu portátil, y trabajaremos juntos en el desarrollo del proyecto de nuestro interés. Si los asistentes tienen interés puedo improvisar un taller de git, para el control de versiones del código fuente, de github como plataforma de colaboración en proyectos de software libre, o en general sobre el proceso de liberación de proyectos de software y desarrollo de las comunidades.
 Cómo llegar a Medialab
Cómo llegar a MedialabAnímate
Apúntate ya en la web, las plazas son muy limitadas.
Si además estás interesado en traer tu proyecto es importante que lo comuniques cuánto antes, así podrá colocarse en la página web y atraer la atención de potenciales colaboradores. Si tienes dudas al respecto ponte en contacto con la organización (o conmigo).

Uno de los aspectos a estudiar durante el análisis de la gestión de datos de investigación en el INIA son las reticencias, problemas o desventajas que encuentran los investigadores a la hora de compartir sus datos. La mayoría son los esperados, y comunes a la mayoría de las áreas de investigación:
- Pérdida de competitividad (al permitir el acceso a investigadores "rivales").
- Falta de reconocimiento al tiempo dedicado a su publicación.
Un problema que no esperabamos es el del anonimato. En algunos campos de investigación, los científicos pueden acceder a información o realizar experimentos o medidas con la condición que los datos no se hagan públicos. Pensemos en el caso de estudios médicos en el que los pacientes no quieren ser identificados, pero el problema es extensible a estudios financieros, comerciales, de seguridad informática, de producción animal, ... Los colaboradores (enfermos, empresas, criadores) desean que se realicen estudios que les permitan un mejor conocimiento de su sector, y la solución a alguno de sus problemas; pero no desean que sus datos sean públicos. Si están dispuestos a que los datos sean públicos de manera agregada como parte de los resultados de la investigación.
Por otro lado, los investigadores de estos sectores podrían avanzar en su investigación si pudieran acceder a los datos que otros colegas hubieran publicado con anterioridad; pero que no han hecho por la limitación impuesta por sus colaboradores.
Esto me ha llevado a pensar durante un tiempo en estrategias para anonimizar los datos científicos. Mi idea general es la de un sistema que mantiene la información individualizada, pero que usa una colección de claves públicas y privadas por dataset de manera que aún accediendo a los datos no se pueden relacionar con los de otras tablas. Por otro lado, el sistema es capaz de devolver datos agregados conforme a unas restricciones (temporales, espaciales, de volumen de la información utilizada) de forma que los usuarios pueden realizar consultas agregadas sin acceder a la totalidad de la información. Un sistema de este tipo, si bien está descrito a muy alto nivel, garantiza:
- el anonimato, al no poder identificar los registros de los dataset con los individuos del estudio
- la reusabilidad, al almacenar la información particular de los individuos, y ofrecer un sistema de consultas agregadas con tablas de otros datasets.
Por el momento, no he encontrado un sistema con estas características, aunque he descubierto el trabajo de DNAdigest, una organización británica sin ánimo de lucro dedicada a promover que los investigadores publiquen y compartan los datos genéticos de sus estudios, mientras se mantiene la privacidad de los individuos participantes.
La aproximación que hacen al problema viene descrita en el workshop que impartieron en septiembre de 2013 es similar a la que había pensado, aunque más génerica si cabe, ya que plantea una API, una interfaz común que permitiría el acceso a diferentes repositorios de información (genética en este caso) manteniendo la confidencialidad de los participantes.
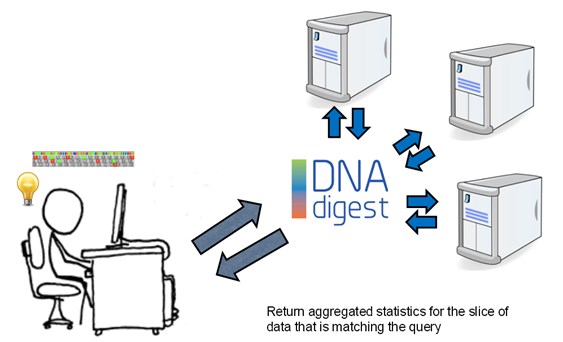
Supongo que es el momento de averiguar cuál es el estado de desarrollo de este sistema y cómo podemos implementar dicha API en la estrategia de gestión de datos de investigación del INIA, de forma que nuestros investigadores puedan sacar el mayor partido de compartir los datos de investigación manteniendo la confidencialidad y el anonimato de los socios participantes.
Y los lectores de este blog, ¿pensáis que os podéis beneficiar de un sistema de este tipo, accediendo a la información pertinente de otros estudios sin necesidad de un acceso a los datasets completos? ¿habéis sufrido casos en los que sabéis que existen estudios que podrían ayudar a confirmar los vuestros, pero no es posible acceder a sus datos experimentales por estos motivos? ¿cómo lo habéis resuelto? ¿cómo compartis vuestra información cuando se os requiere en uno de estos casos? ¿en que casos lo hacéis? Dejad vuestras experiencias e ideas en los comentarios de la página.

El martes 28 de julio me acerqué a las instalaciones del Campus Madrid de Google para dar una charla sobre git a los amigos de H4ckademy. H4ckademy es un programa de formación de desarrolladores a través de un proyecto que les ayuda simultáneamente a crear un portfolio y a ponerse al día con herramientas y buenas prácticas en el desarrollo de software moderno.
La charla fue de un nivel muy introductorio, pero se estableció al final un turno de preguntas bastante interesante.
Aquí tenéis un acceso a las transparencias que utilicé:
http://slides.com/ajspadial/git-a-life
Y los comentarios y fotografías que han compartido en las redes sociales:
Para el desarrollo de la charla he usado material del manual de git, y de la introducción a git de Software Carpentry. Creo que la charla tiene potencial para transformarse en un curso/taller introductorio de git. La charla estaba orientada a gente que quiere dejar de sentirse como en:
 "Piled Higher and Deeper" by Jorge Cham
"Piled Higher and Deeper" by Jorge Cham
www.phdcomics.com
Y vosotros, ¿os habéis sentido alguna vez como el estudiante del cómic? ¿Creéis que un taller de este tipo os puede ser de utilidad en vuestro trabajo con código u otras fuentes? Deja un comentario y cuéntanos cómo te pueden ayudar estas herramientas.
El pasado viernes 22 de junio (de 2018), se celebró en el marco de la feria Smart AgriFood Summit en Málaga, un debate organizado por la D.G. de Desarrollo Rural del Ministerio de Agricultura, Pesca y Alimentación sobre Los modelos de adopción de TICs en el sector agroalimentario
No, de verdad que no era un chupito
Durante el debate discutimos qué factores, agentes y estrategias pueden impulsar o fomentar la digitalización del sector rural, y sus resultados estarán integrados en las acciones y estrategias que apareceran en la próxima Agenda Digital del ministerio.
Como parte de la introducción al debate, hice la siguiente exposición sobre el impacto de los datos abiertos en la adopción de las TICs.
IMPACTO DE LOS DATOS ABIERTOS EN LA ADOPCIÓN DE TECNOLOGÍAS Y SERVICIOS DIGITALES EN EL SECTOR RURAL
¿Qué son los datos abiertos?
Conforme a la definición de Wikipedia, son datos publicados para su reutilización, sin necesidad de permisos específico.
Se publican bajo una licencia abierta que aclare las condiciones de uso, p.ej: solicitando la cita del origen de los datos para su reutilización.
¿Qué tipos de datos abiertos hay?
Podemos describir los datos abiertos conforme a una serie de características. La más destacable es el dominio, o asunto, sobre el que tratan esos datos. En el sector agroalimentario hay muchos ejemplos de dominios de interés: datos meteorológicos, de suelos, de precios, ...
También es interesante conocer la precisión y la frecuencia de las medidas, los procedimientos de cálculo o muestreo, o el formato de los ficheros.
Por último, frecuentemente es de interés conocer el origen de los datos, siendo frecuentemente publicados por las administraciones públicas, pero también por las universidades y centros de investigación, y en menor medida, pero de manera creciente, por los particulares y otros agentes del sector.
¿Cómo impactan los datos abiertos en la adopción de las TICs?
Los datos en general, son un bien complementario a las tecnologías y servicios digitales. Es decir, que los incrementos en su oferta, o su demanda, llevan asociados crecimiento en la oferta, o la demanda, de las tecnologías y los servicios digitales. La publicación de los datos abiertos de Copernicus es un buen ejemplo del aumento de la oferta de servicios digitales impulsada por el aumento de la oferta de datos abiertos.
¿Cuál es el impacto de los datos abiertos en la adopción de las tecnologías digitales?
El deseo de acceder, explotar o integrar conjuntos de datos abiertos va a impulsar la adopción de tecnologías digitales que lo faciliten. La capacitación en el uso de estas tecnologías será crucial, así como el desarrollo de tecnologías con mayor facilidad de uso.
El impacto específico de los datos en la adopción de estas tecnologías a depender del coste/beneficio real y percibido, incluyendo en este coste la capacitación en su uso.
¿Cuál es el impacto de los datos abiertos en la adopción de servicios digitales?
El acceso a datos abiertos reduce la barrera de entrada para el lanzamiento y mejora de servicios digitales.
Pueden nuevos servicios generalistas o sectoriales, pero también servicios ultra-locales. En general, la aparición de estos servicios ultra-locales que aunan el conocimiento de las necesidades específicas del sector en determinado nicho de mercado o comarca es uno de los factores de interés para el desarrollo rural del impulso a las iniciativas de datos abiertos.
¿Cómo podemos impulsar la publicación y reutilización de datos abiertos?